Die Evolution der JavaScript-Engine von Firefox
Im Jahre 1995 schrieb Brendan Eich die erste Implementierung von JavaScript innerhalb von 10 Tagen. Seitdem wird Mozillas JavaScript-Engine, genannt SpiderMonkey, immer weiter verbessert und angepasst. Während in den Anfgangsjahren das Hauptinteresse noch auf der Entwicklung neuer Features lag, wurde bald deutlich, dass JavaScript wegen seiner gehäufte Nutzung im Internet beschleunigt werden muss, um nicht neue Entwicklungen zu lähmen. Spätestens seit der Veröffentlichung von Google Chrome, mit seiner zur damaligen Zeit unvergleichbar schnellen JavaScript-Engine V8, ist ein wahrer Geschwindigkeits-Krieg entbrannt. Dies hatte die positive Folge, dass man sich heute kaum noch Sorgen darum machen muss, ob seine JavaScript Anwendungen auch schnell genug ausgeführt werden.
SpiderMonkey – der Interpreter
Einigermaßen unintuitiv wird der Interpreter SpiderMonkey genannt, genauso wie die gesamte Engine, die heute aus mehreren Teilen besteht. Wie der Name bereits andeutet, interpretiert ein Interpreter etwas. Sprich, es wird JavaScript Code ausgeführt. Hierbei wird jedoch nicht, wie man vielleicht annehmen könnte, direkt mit dem Quellcode gearbeitet, sondern dieser wird in einen so genannten Bytecode übersetzt.
Hierzu ein kleines Beispiel. Nehmen wir den folgenden recht einfachen Code, welcher den Umfang eines Quadrates zurück gibt.
function umfang (a) {
return a * 4;
}
Als Bytecode würde das ungefähr so aussehen.
0000: getarg 0
0003: int8 4
0005: mul
0006: return
Dabei ist das nur eine symbolische Schreibweise für den eigentlichen Bytecode, in dem z.B. der Befehl getarg durch das Byte 0x84 und int8 durch das Byte 0xD8 dargestellt wird. Damit ist klar, dass die obenstehenden „Zeilennummern“ die Bytes zählen und die ersten beiden Zeilen sind hexadezimal aufgeschrieben
84 00 00 D8 04
Der Interpreter führt den Bytecode Schritt für Schritt aus, dabei wird das Ergebnis jedes Befehls auf einem Stack abgelegt. Das bedeutet: getarg 0 legt den als Argument a übergebenen Wert auf den Stack. Danach legt der Befehl int8 die ganze Zahl (engl. integer) 4 auf den Stack; die 8 im Befehlsnamen gibt an, dass die Zahl 8 Bits Platz einnimmt. mul entfernt die zwei obersten (bzw. als letztes hinzugefügten) Werte vom Stack, multipliziert sie und legt das Ergebnis wiederum auf den Stack. Hierbei spricht man auch von einem Stack-basierten Interpreter.
Hier ein kleines Beispiel eines in JavaScript implementierten Interpreters, der die Array-Methoden push und pop benutzt, um einen simplen Stack zu simulieren. Die Variable
pc (Process Counter) repräsentiert dabei den nächsten Befehl, der ausgeführt
werden soll.
function execute (bytecode, args) {
var stack = [];
var pc = 0;
do {
var op = bytecode[pc];
switch (op.inst) {
case 'getarg':
stack.push(args[op.arg]);
break;
case 'int8':
stack.push(op.int);
break;
case 'mul':
var rhs = stack.pop();
var lhs = stack.pop();
stack.push(lhs * rhs);
break;
case 'return':
return stack.pop();
}
pc++;
} while (true);
}
Interaktion:
execute([
{inst: 'getarg', arg: 0},
{inst: 'int8', int: 4},
{inst: 'mul'},
{inst: 'return'}
], [10]);
Vergleicht man den Rückgabewert dieses Funktionsaufrufs mit umfang(10) so sind diese in der Tat identisch. Denkt man nun ein wenig weiter über diesen Mini-Interpreter nach, fällt einem vielleicht auf, dass sehr viel Zeit damit verschwendet wird, herauszufinden, was für eine Instruktion ausgeführt werden soll. Und dies ist exakt einer der Hauptprobleme eines Interpreters – es wird einfach zu viel Zeit dafür verwendet, herauszufinden, was getan werden soll. Was nicht im oben stehenden Code ersichtlich ist, aber zusätzlich Zeit kostet, ist, dass beim Zwischenspeichern auf dem Stack wichtige Informationen verloren gehen. Etwa, ob es sich bei dem Parameter a um einen String oder ein Objekt handelt.
Ein Interpreter hat aber auch Vorteile, er ist in der Regel einfacher anzupassen als ein Compiler. So wird der Interpreter in SpiderMonkey häufig dafür genutzt, neue Vorschläge für ECMAScript schnell testen zu können. Das hat aber auch zur Folge, dass manche Operationen, die einfach zu komplex sind, im Verhältnis dazu, wie oft sie verwendet werden, selten in einem der beiden JITs (siehe unten) implementiert werden.
TraceMonkey – der Tracing JIT
Die Entwicklung von TraceMonkey begann im Jahr 2008 und wurde in Firefox 3.5 zum ersten Mal eingesetzt. Hierbei geht man von der Annahme aus, dass der meiste Code immer mit den selben Typen ausgeführt wird. Praktisch bedeutet das, dass der Bytecode ausgeführt wird wie durch den Interpreter, dabei jedoch Maschinencode erzeugt. Und zwar nur für den Typ, den man bei diesem einen „Durchlauf“ beobachtet hat. Das nennt man auch „just in time (JIT) compilation“, ein Just-In-Time-Compiler wird abkürzend auch als JIT bezeichnet.
Kehren wir zurück zur Funktion umfang und gehen von dem Fall aus, dass die Funktion mit 10 (einer ganzen Zahl, engl. integer) als Parameter a aufgerufen wird. Der Tracing JIT würde nun für die Instruktion mul zwei Integerwerte beobachten (4 und 10) und Maschinencode für die Multiplikation von zwei Integerwerten erzeugen. Wenn jetzt aber a jemals ein String wird, würde das natürlich ein falsches Ergebnis liefern, da man einen String nicht auf dieselbe Art multiplizieren kann wie einen Integerwert. Dasselbe passiert auch, wenn man zu einer if-Bedingung gelangt. Falls sie wahr ist, wird nur das Innere des if-Blocks ausgeführt und in Maschinencode übersetzt. Ist nun die ganze Funktion „aufgenommen“ und als Maschinencode gespeichert (hier spricht man von tracing, deshalb auch Tracing JIT), wird beim nächsten Mal nicht Bytecode vom Interpreter, sondern Maschinencode direkt vom Prozessor ausgeführt.
Dieses Verfahren generiert zwar sehr schnellen Code. Sind aber die Typen anders oder ist eine if-Bedingung, die während des Aufnehmens wahr war, nun falsch, muss abgebrochen werden und der Code wieder durch den langsamen Interpreter ausgeführt werden. Der entstehende Maschinencode ist linear, da er genau den Weg (Trace) darstellt, den das Programm beim Aufnehmen genommen hat. Andreas Gal, der Tracing JITs erforscht, fand eine Lösung, die den Rückgriff auf den Interpreter vermeidet, wenn sich der Kontrollfluss ändert (beispielsweise bei Ausführung eines anderen if-Zweiges): Es wird einfach eine weitere Aufnahme gemacht und erneut Maschinencode generiert. Dabei ensteht ein sogenannter Trace-Tree, also ein Baum, in dem jede Verzweigung eine if-Bedingung oder eine andere Kontrollstruktur darstellt. Gibt es zu viele dieser Verzweigungen, wird die Ausführung des Programms stark verlangsamt (trace explosion).
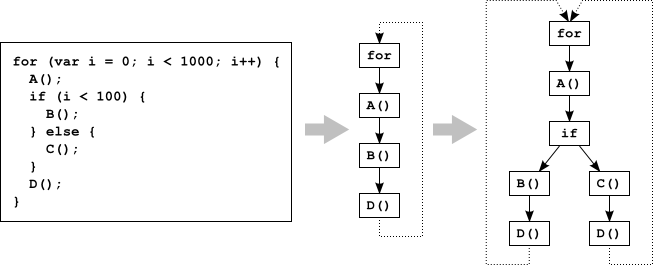
Der erste Trace (mitte) ist noch streng linear und gültig, so lange i < 100. Sobald jedoch
i === 100, muss ein zweiter Trace (rechts) aufgenommen werden.
Die beiden entstehenden Äste werden durch einen if-Knoten verknüpft.
[Quelle des Bildes: „SpiderMonkey: rychlá kompilace JavaScriptu do nativního kódu“ von David Majda.]
In manchen Fällen gab es eine 20- bis 40-fache Beschleunigung. Jedoch musste man leider feststellen, dass viele JavaScript-Programme sich einfach nicht aufnehmen lassen – einer der Gründe warum JägerMonkey entwickelt wurde. Ende 2011 wurde TraceMonkey aus SpiderMonkey entfernt, da er andere Optimierungen behinderte und nicht effektiv genug war.
JägerMonkey – der Method JIT
Um mehr Code schnell ausführen zu können, wurde im Jahr 2010 ein so genannter Method JIT entwickelt. Anstatt wie bei einem Tracing JIT nur den JavaScript-Code zu kompilieren, der während des Aufnehmens ausgeführt wurde, wird in JägerMonkey immer für eine ganze Funktion oder Methode Maschinencode generiert. Das bedeutet aber auch, dass Jägermonkey mit allen Datentypen umgehen können muss, die bei einer Operation vorkommen können.
function add (a, b) {
return a + b;
}
In diesem Beispiel kann der Operator + sehr unterschiedliches bedeuten: Wenn es sich bei
a und b um Zahlen handelt, wird addiert. Sind es jedoch Strings, werden
diese aneinander gehängt. Bei Objekten müssen sogar die Methoden valueOf bzw.
toString aufgerufen werden.
Da es meist jedoch kein Sinn macht, für alle Möglichkeiten Code zu generieren, kümmert sich
JägerMonkey nur um Datentypen, die häufig in Verbindung mit der jeweiligen Operation vorkommen.
So wird zum Beispiel Maschinencode für die Multiplikation (*) von zwei Zahlen generiert,
aber nicht für den unwahrscheinlichen Fall, dass jemand mit null multipliziert. Dafür wird wieder der Interpreter bemüht.
Aufgrund dieser Eigenschaft kann fast für jedes JavaScript-Programm Maschinencode generiert werden. Im Gegensatz dazu hatte der Tracing JIT oft das Problem, dass er zwar eine Funktion zu 99% optimieren konnte, dann aber eine Operation beobachtet wurde, die es unmöglich machte, die gesamte Funktion zu kompilieren. In anderen Fällen hat das Optimieren zwar erst funktioniert, dann aber wurde die Funktion mit vielen verschiedenen Datentypen ausgeführt. Das ist etwas mit dem ein Tracing JIT selbst mit einem Trace-Tree nicht gut umgehen kann. JägerMonkey hat dieses Problem nicht. Würde eine Funktion zum Beispiel doch einmal mit null multiplizieren, aber sonst hundertmal mit einer Zahl, ist dies immer noch sehr schnell, und nur die Multiplikation mit null langsamer.
Das lässt sich gut erkennen, wenn wir den generierten Maschinencode für eine Multiplikation in JavaScript darstellen.
function multiply(left, right) {
if (left.isInt) {
if (right.isInt) {
return left.int * right.int;
}
if (right.isDouble) {
return convertToDouble(left.int) * right.double;
}
}
if (left.isDouble) {
if (right.isDouble) {
return left.double * right.double;
}
if (right.isInt) {
return left.double * convertToDouble(right.int);
}
}
return slowMultiply(left, right);
}
Typinferenz – dynamisch-statische Typ-Analyse
Seit Firefox 9 besitzt SpiderMonkey ein neu entwickeltes Feature, das Typinferenz (TI) genannt wird. TI ist in der Lage, zur Übersetzungszeit zu berechnen, welche Datentypen wo vorkommen können. Mit Hilfe der gewonnenen Typ-Information kann JägerMonkey spezialisierten Maschinencode generieren. Etwa, um auf unser vorheriges Beispiel zurück zu kommen, nur für die Multiplikation zweier ganzen Zahlen. Das hat den großen Vorteil, dass JägerMonkey nicht erst die Typen der beiden Operanden überprüfen muss. Es liegt jedoch in der Natur von JavaScript, dass nicht alles statisch analysierbar ist. Deshalb muss man in manchen Fällen einfach eine Annahme machen, z.B. was für einen Typ eine bestimmt Funktion zurück gibt. Führt man das Programm dann aus und die Funktion gibt einen anderen Typ zurück, muss das Programm erneut analysiert werden.
Vergleichen wir jetzt den Maschinencode für die Multiplikation vor und nach TI, ist es offensichtlich, wie sehr das häufige Überprüfen des Datentyps die Performance beinflusst.
function multiply(left, right) {
return left.int * right.int;
}
Fazit
Wie man sehr gut sieht, geht die Entwicklung von SpiderMonkey mit enormem Tempo voran. So wird es bald IonMonkey geben, der noch einmal alles verändern wird. Er macht sich Optimierungen zu Nutze, die sonst nur von „großen“ Compilern wie gcc oder der Java Virtual Machine verwendet werden. In Zukunft gibt es wohl kaum noch Anwendungen, die durch ein zu langsames JavaScript ausgebremst werden. Und Themen, über die man an dieser Stelle berichten könnte, gibt es auch noch genügend.
 Tom Schuster besucht zur Zeit die 12. Klasse eines technischen
Gymnasiums. In Alter von 10 Jahren war JavaScript die erste
Programmiersprache mit der er in Berührung kam. 2008 fing er, an sich
dafür zu interessieren, wie andere ausführbare Programme
funktionieren. Daraus folgte eine Passion für Reverse Engineering,
sowie Assembler und Low-Level-Programmiersprachen.
Seit 2010 ist er ein Contributor bei Mozilla und unterstützt dort
vor allem die Entwicklung der JavaScript-Engine SpiderMonkey.
Tom Schuster besucht zur Zeit die 12. Klasse eines technischen
Gymnasiums. In Alter von 10 Jahren war JavaScript die erste
Programmiersprache mit der er in Berührung kam. 2008 fing er, an sich
dafür zu interessieren, wie andere ausführbare Programme
funktionieren. Daraus folgte eine Passion für Reverse Engineering,
sowie Assembler und Low-Level-Programmiersprachen.
Seit 2010 ist er ein Contributor bei Mozilla und unterstützt dort
vor allem die Entwicklung der JavaScript-Engine SpiderMonkey.
Tom Schuster bloggt auf javascript.reverse() und tweetet als @evilpies.